Testing the accuracy of species distribution models using species records from a new field survey
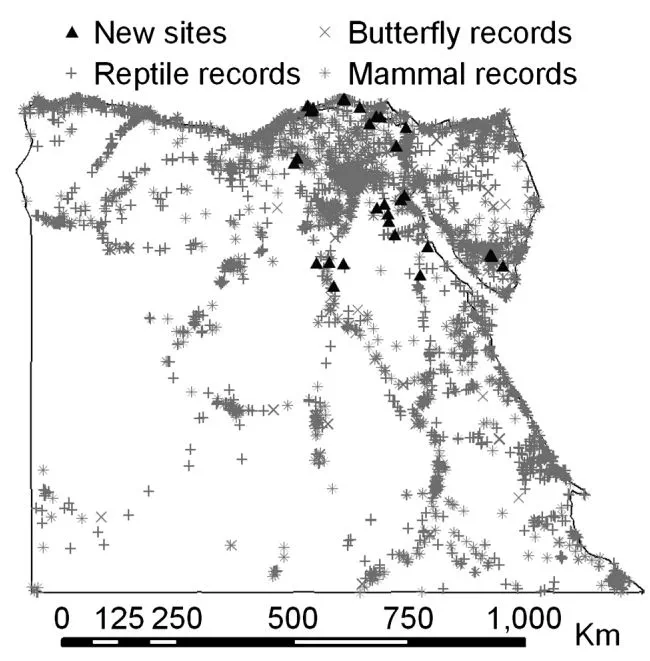
Species distribution models are a very popular tool in ecology and biogeography and have great potential to help direct conservation efforts. Models are traditionally tested by using half the original species records to build the model and half to evaluate it. However, this can lead to overly optimistic estimates of model accuracy, particularly when there are systematic biases in the data. It is better to evaluate models using independent data. This study used independent species records from a new to survey to provide a more rigorous evaluation of distribution-model accuracy. Distribution models were built for reptile, amphibian, butterfly and mammal species. The accuracy of these models was evaluated using the traditional approach of partitioning the original species records into model-building and model-evaluating datasets, and using independent records collected during a new field survey of 21 previously unvisited sites in diverse habitat types. We tested whether variation in distribution-model accuracy among species could be explained by species detectability, range size, number of records used to build the models, and body size. Estimates of accuracy derived using the new species records correlated positively with estimates generated using the traditional data-partitioning approach, but were on average 22% lower. Model accuracy was negatively related to range size and number of records used to build the models, and positively related to the body size of butterflies. There was no clear relationship between species detectability and model accuracy. The field data generally validated the species distribution models. However, there was considerable variation in model accuracy among species, some of which could be explained by the characteristics of species.