Wrong, but useful: regional species distribution models may not be improved by range-wide data under biased sampling
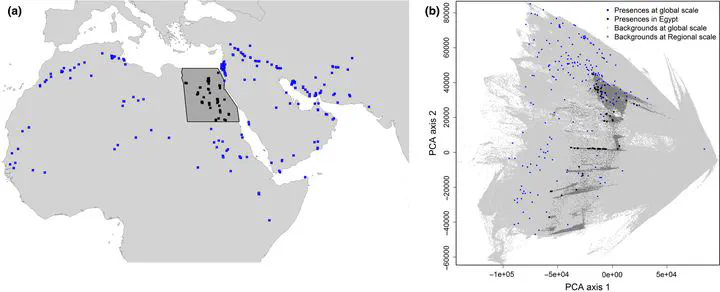
Species distribution modeling (SDM) is an essential method in ecology and conservation. SDMs are often calibrated within one country’s borders, typically along a limited environmental gradient with biased and incomplete data, making the quality of these models questionable. In this study, we evaluated how adequate are national presence‐only data for calibrating regional SDMs. We trained SDMs for Egyptian bat species at two different scales: only within Egypt and at a species-specific global extent. We used two modeling algorithms: Maxent and elastic net, both under the point-process modeling framework. For each modeling algorithm, we measured the congruence of the predictions of global and regional models for Egypt, assuming that the lower the congruence, the lower the appropriateness of the Egyptian dataset to describe the species’ niche. We inspected the effect of incorporating predictions from global models as additional predictor (“prior”) to regional models, and quantified the improvement in terms of AUC and the congruence between regional models run with and without priors. Moreover, we analyzed predictive performance improvements after correction for sampling bias at both scales. On average, predictions from global and regional models in Egypt only weakly concur. Collectively, the use of priors did not lead to much improvement: similar AUC and high congruence between regional models calibrated with and without priors. Correction for sampling bias led to higher model performance, whatever prior used, making the use of priors less pronounced. Under biased and incomplete sampling, the use of global bats data did not improve regional model performance. Without enough bias-free regional data, we cannot objectively identify the actual improvement of regional models after incorporating information from the global niche. However, we still believe in great potential for global model predictions to guide future surveys and improve regional sampling in data‐poor regions.